Gesture-Based Control Interface for Virtual Robots using Few-Shot Learning
Nathan Chung, Wesley Ford, Pranav Kuppili, Theodoros Zournatzis
1. Introduction
Robots continue to increase their physical and psychological footprint in society. Human-Robot Interaction (HRI) is critical to ensure that humans accept robots into their environment, comforting them with a sense of ease, safety, familiarity, and control. However, traditional methods for interacting with robots often are implemented via manufactured controllers: keyboards, joysticks, or tablets. While such controllers provide fine-tuned, granular control, they can be unintuitive to those unfamiliar with the platform they are interacting with. In addition, it would be infeasible to equip everyone who may interact with a robot with such a controller.
Opposed to traditional methods are gesture controllers which utilize natural human movements to express the desired high-level actions the robot is to perform. Such gestures offer the potential for intuitive interactions between humans and robots, as a population tend to use similar hand-gestures to express that same intent, and are a natural way that humans express themselves to other humans.
We propose a camera-based gesture controller that will enable humans interacting with a robot equipped with this controller to use simple hand motions to direct a robot and control its motion. For such a system to be feasible, it must be able to adapt to a wide range of user variability. Although general hand-gestures may be common, the way they are performed by individuals may vary widely, despite the same general action and intent. To accomplish adaptability to different user styles , we investigate utilizing Few-Shot Learning (FSL) to recognize gestures. FSL requires small numbers of labeled examples to infer general trends in the provided data. This enables a gesture classifier to quickly adapt to distinct user styles without vast amounts of data, the collection of which would be infeasible for individual users to produce and tailor the control to their gestures.
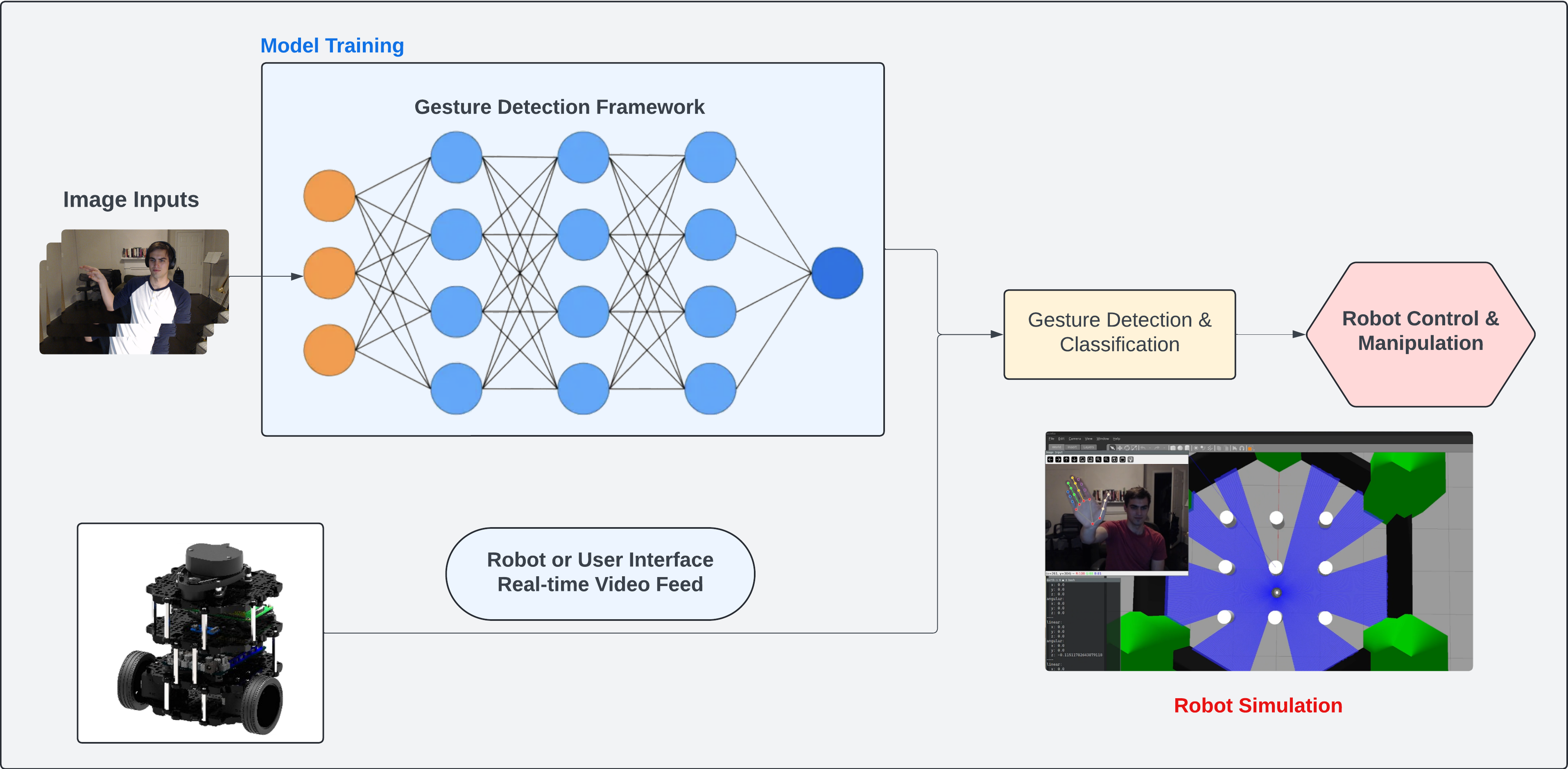
Figure 1: Project Overview.
2. Related Works
Human-Robotic Interface (HRI) is a widely researched concept and many research groups have worked in this field. Additionally, when looking further into gesture recognition and gesture-based control of a robot, there are many similar projects as well, many of which have similar approaches. In addition, there are many different approaches and papers for Few-Shot Learning (FSL) as it is a very popular emerging technology.
2.1 Hand gesture based control strategy for mobile robots
To start, a research group enhanced the field of HRI by combining hand gestures and control interfaces for robots by using 5 static hand gestures to control the mobile robot. To understand the gesture that the user was signaling, the researchers first used color segmentation and some non-linear and linear filtering techniques before obtaining the contour of the hand using OpenCV [1]. Only static simulation images were provided for the mobile robot movement. The static simulation of images may be a useful approach for us and our project.
2.2 Gesture Recognizer
Research in this field is not only limited to working with gestures and robots but also to the creation of computer vision models and other tools to foster more work in this field. One such group is Google with MediaPipe. MediaPipe is Google’s repository of computer vision models that offers solutions such as hand tracking, pose detection, and object detection [2]. While the use cases for their machine learning models are broad and non-targeted, their gesture recognition models can be trained with custom datasets and tuned for specific use cases. Using a model like MediaPipe can be a good approach to benchmark our gesture recognition model.
2.3 Hand Gesture Interface for Robot Path Definition in Collaborative Applications: Implementation and Comparative Study
A different approach for the integration of gesture recognition and control interfaces for robots utilizes the aforementioned tool, MediaPipe. Researchers used computer vision to detect the gestures using a camera and MediaPipe, from which the robots were able to execute actions. The data is transmitted from the camera to the control interface by using ROS [3]. Studying this group’s approach to using MediaPipe may be useful for our project, as well as what the group implemented afterward with ROS.
2.4 Learning from few examples: A summary of approaches to few-shot learning
In addition to gesture recognition and using gestures for robotics, there are many papers and architectures for few-shot learning. Few-shot learning is essentially where the data set is drastically smaller than a normal training set for a neural network model. There can be many different architectures for this type of learning such as Convolutional Siamese Networks, Prototypical Networks, Relation Networks, and more [4]. Studying these types of papers can help us understand how to properly utilize an architecture that works well with FSL and helps us achieve high accuracy.
2.5 Fast Learning of Dynamic Hand Gesture Recognition with Few-Shot Learning Models
Lastly, a research group was focused on hand gesture recognition with few-shot learning. This research group focused on creating a FSL model by utilizing the Relation Network and were able to get an accuracy of up to 88.8% [5]. In addition, this group was also able to use Google’s MediaPipe to assist with the process of gesture recognition. Learning from a similar project for Gesture Detection using FSL can help us gain a lot of insight into how to choose a good architecture for our learning models.
All of these papers have either focused on gesture recognition as a control interface for a robot, or creating a gesture recognition model using Few-Shot Learning. However, the goal of this project is to combine both of these ideas to use a Few-Shot Learning Model to create a gesture recognizer, which then can further act as a control interface for a robot through means of ROS. Utilizing all of this previous research, we were able to develop an understanding and idea of how we were going to pursue this project of gesture-based control with Few-Shot Learning.
3. Methods/ Approach
Few-Shot Learning (FSL) is pivotal in our approach to gesture recognition. FSL operates under the premise that models can learn to generalize from a minimal number of examples—often as few as two to five samples per class. This framework is especially suited to our project, given the vast array of potential gestures and the impracticality of extensive data collection for each. In the context of our work, FSL involves constructing a support set, consisting of a small number of labeled images representing specific gestures, and a query set, comprising images for which the gesture needs to be recognized [6][7].
3.1 Dataset Description
In the initial stages of our project, we utilized the Jester Dataset [8], which comprises 148,092 video clips of humans performing simple, predefined hand gestures. This extensive dataset, provided by Qualcomm, includes 27 distinct classes of hand gestures such as directional swipes and stop signs, making it highly suitable for intuitive control interfaces for mobile devices and 6-DOF robotic arms. Despite its comprehensive nature and diversity, we encountered a significant limitation due to the predominance of low-resolution and low-quality images within the dataset.
To overcome this challenge and enhance the quality of our gesture recognition system, we decided to compile our own dataset to replace the Jester dataset, focusing on higher-resolution images. We used webcams to capture new, high-quality images that would support the refined needs of our few-shot learning framework.

Figure 2: Sample images for each class from our own dataset.
Our custom dataset specifically targets six gesture classes deemed most effective for controlling robotic movements: (0) no gesture, (1) other gesture, (2) stop gesture, (3) swipe left, (4) swipe right, and (5) swipe up. Each gesture is illustrated in Figure 2. To build this dataset, each of the four team members contributed by capturing five images for each of the six classes, resulting in a total of 120 images. These were distributed evenly across the classes to maintain a balanced dataset. Finally, based on the model being implemented, the images were subsequently split into training and testing sets, or support and query sets, correspondingly.
3.2. Data Preprocessing
For preprocessing, we utilized MediaPipe [9], a cutting-edge machine learning framework for building multimodal applied machine learning pipelines, such as pose estimation and object classification. Specifically, we applied MediaPipe’s hand landmark model to extract 21 key hand-knuckle coordinates from the static image frames (Figure 3). This model, trained on approximately 30,000 real-world images and several synthetic models, provides a robust foundation for accurately identifying hand gestures by focusing on the relevant features and eliminating background noise.
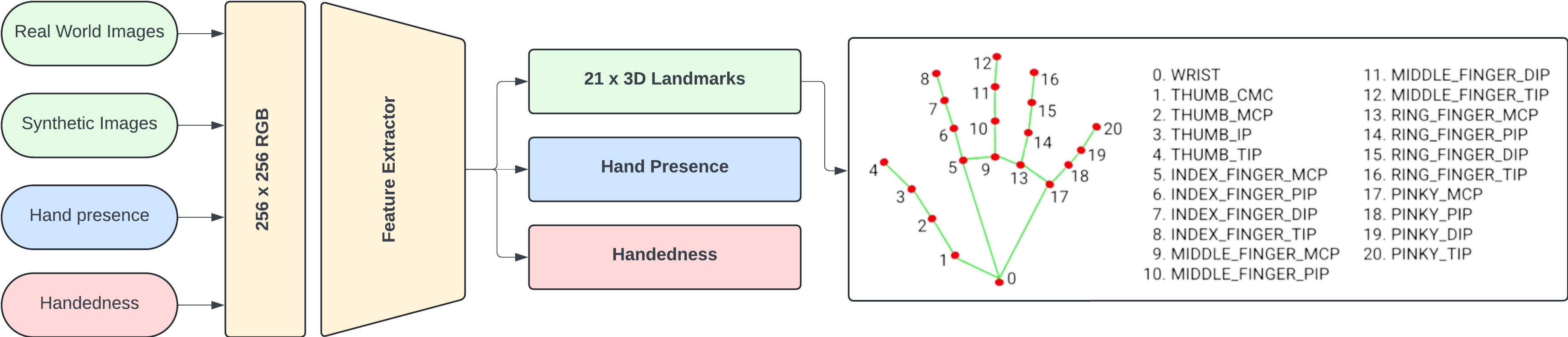 Figure 3: Overview of Data Preprocessing with MediaPipe
Figure 3: Overview of Data Preprocessing with MediaPipe
We chose MediaPipe due to its high accuracy and efficiency in real-time hand landmark detection, critical for the responsiveness of our gesture-based control interface. Furthermore, MediaPipe offers a pre-trained model specifically designed for hand tracking, which greatly accelerates our development process by eliminating the need for extensive training on our part.
In our implementation, we utilized MediaPipe version 0.10.9 to establish a consistent processing environment. We configured the hand detection module (mp_hands.Hands) to operate in static_image_mode, allowing us to process individual image frames with high precision. We set the module to detect only the most prominent hand in an image (max_num_hands=1) to maintain focus on the primary gesture, with a minimum detection confidence of 0.5 to ensure reliability.
Overall, our preprocessing code includes functions to detect hands in images and crop around the detected hand, ensuring that subsequent processing stages focus exclusively on the relevant hand gesture data. If a hand is detected, the function calculates the bounding box around the hand, adjusted by a specified margin, and crops the image accordingly. This margin ensures that the model accounts for slight movements outside the immediate hand area, enhancing the robustness of gesture recognition.
3.3 Implemented Methods
3.3.1 Simese Network
Model Overview. With our first gesture recognition system, we used a Siamese Network to classify our hand gesture classes. In a Siamese network, a pretrained model with the last fully connected layer removed is used as a feature extractor for the model. These features are then fed into our own fully connected layers to train the model on the similarity between two images [10]. This decision is grounded in the Siamese Network’s ability to learn a metric space in which distances directly correspond to a measure of object similarity. In other words, Siamese Networks are particularly apt for few-shot learning tasks due to their design for assessing similarity or dissimilarity between pairs of inputs. Usually, Input 1 of the model is reserved for the support set, which is a collection of images that contain our ‘few-shot’ examples. In this case, our network uses 3-shot learning, so our support set consisted of 3 example images of each gesture class, resulting in a support set of 18 images. Input 2 is our query set, which is a collection of images that are used to compare against the support set. Once the 2 images go through the feature extractor and fully connected layers/similarity function, the similarity score is obtained by a sigmoid activation function to classify the similarity on a scale from 0 to 1.
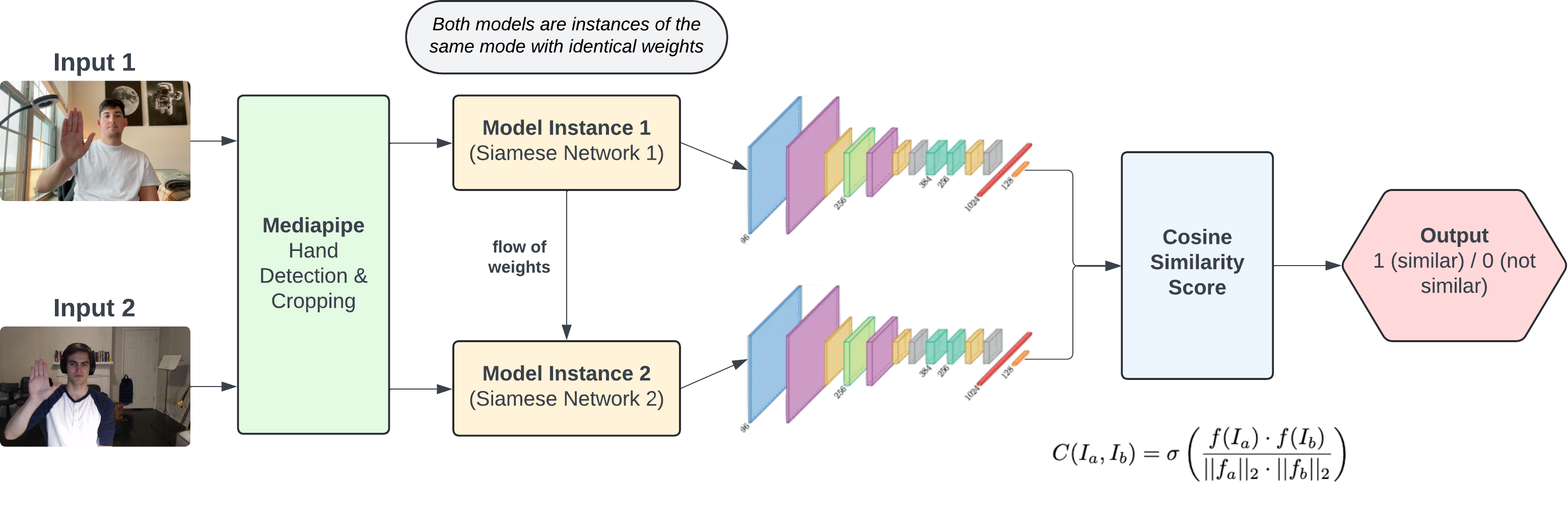 Figure 4: Overview of Siamese Network. Both models are instances of the same mode with identical weights.
Figure 4: Overview of Siamese Network. Both models are instances of the same mode with identical weights.
Mathematically, the cosine similarity C with the sigmoid activation function between two input images Ia and Ib from the support set and query set, respectively, is computed as:
\[\sigma(C(I_a, I_b)) = \sigma\left(\dfrac{f(I_a)\cdot f(I_b)}{||f(I_a)||_2 \cdot ||f(I_b)||_2}\right)\]$\newline$ where $f(\cdot)$ denotes the feature extraction function of the Siamese network and $\sigma(\cdot)$ represents the sigmoid function. For training our Siamese network we decided to try a few different approaches for our model: pure cosine similarity, a few fully connected layers, and a combination of both. We used Binary Cross Entropy Loss to optimize our model. Once trained, we can take our query images and compare it to every image in the support set and apply a softmax to get the predicted gesture.
Data Augmentation. For Data augmentation, we used PyTorch’s AutoAugment transform to augment our dataset. AutoAugment applies a series of transforms that have been successful with other data sets when training [11]. We used the default policy, which was used for ImageNet.
3.3.2 Pretrained Residual Network (ResNet)
Model Overview. In this gesture recognition system, we employ a modified ResNet (Residual Network) architecture to classify six specific hand gestures. ResNet, originally introduced by He et al. [12] in their seminal 2016 paper, utilizes skip connections or shortcuts to jump over some layers, which helps in alleviating the vanishing gradient problem and enables the training of substantially deeper networks. This architecture has been demonstrated to be highly effective in various computer vision tasks due to its ability to preserve the integrity of the input data through layers. Our approach leverages a pretrained ResNet18 model, which has been shown to provide a strong feature extraction base for various image recognition tasks.
ResNet-18, originally designed for 1000-class ImageNet classification, consists of repetitive residual blocks featuring two convolutional layers each. The model leverages batch normalization and ReLU activations, ensuring stable and accelerated training. For our application (Figure 5), we adapt this architecture by unfreezing the last two convolutional blocks (layer3 and layer4) to fine-tune them specifically for our gesture classification task. We replace the original fully connected output layer with a new linear layer that maps to our six classes:
$\newline$ \(y = Wx + b\) $\newline$
where W and b are the weights and bias of the new fully connected layer, respectively. This modification allows us to leverage the deep feature extraction capabilities of ResNet-18 while tailoring the network’s output to our specific task.
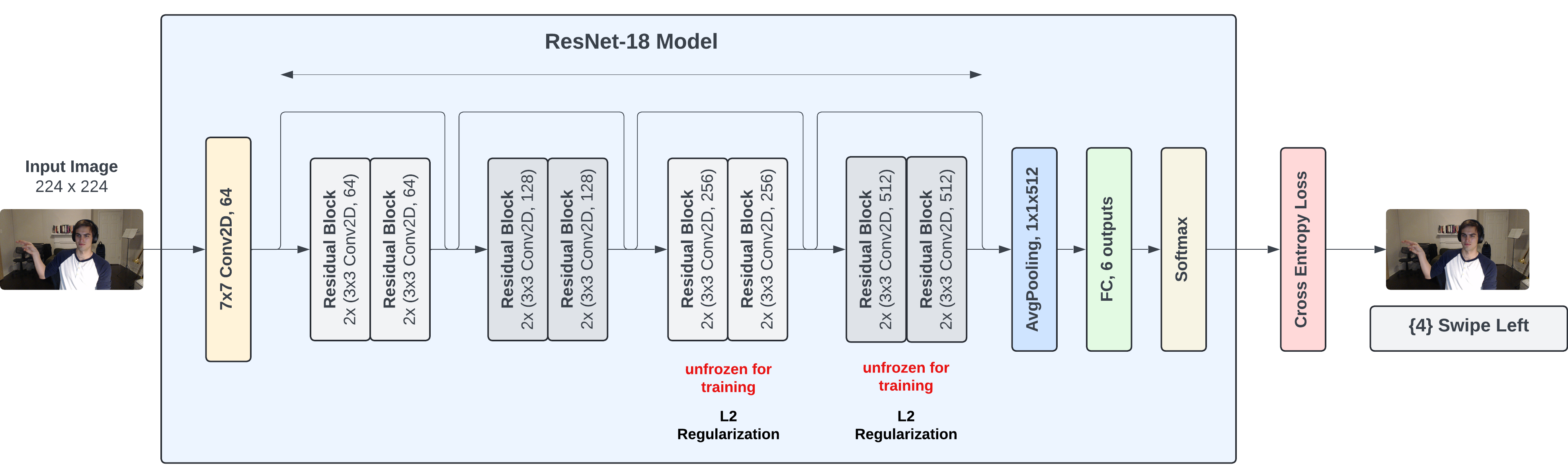 Figure 5: Sample images for each class from our own dataset.
Figure 5: Sample images for each class from our own dataset.
L2 Regularization. To prevent overfitting and ensure the model generalizes well to new, unseen data, we employ L2 regularization in our training process, which adds a penalty term to the loss function equal to the square of the magnitude of the coefficients:
$\newline$ \(\text{Loss}_{L2} = \text{Loss} + \lambda \sum_iw_i^2\) $\newline$
where $\lambda$ is the regularization parameter and $w_i$ represents each weight in the network [13].
Loss Function. For our loss function, we use Cross Entropy Loss, which is particularly suited for multi-class classification problems where each class is mutually exclusive. In a scenario like ours, where each gesture represents a unique class, CrossEntropyLoss effectively measures the performance of our classification model whose output is a probability value between 0 and 1. Cross Entropy Loss combines LogSoftmax and negative log likelihood loss (NLLLoss) in one single class [14]. It calculates the loss by comparing the model’s predicted probabilities with the true class labels, penalizing the probabilities divergent from the actual label. The formula for CrossEntropyLoss is given by:
$\newline$ \(L = \sum_{i=1}^C y_i \cdot \log \left(\hat{y}_i\right)\) $\newline$
where $C$ is the number of classes, $y$ is a binary predictor (0 or 1) if class label $c$ is the correct classification for observation $o$, and $\hat{y}$ is the predicted probability of the class label $c$ for observation $o$. The loss calculation is performed over each instance in the dataset, and the results are averaged. This loss function ensures that the penalty is higher for incorrect classifications with high confidence, which drives the model to correct these errors in subsequent training epochs.
Data Augmentation. Given the variability in human gestures, data augmentation plays a crucial role in training our model to generalize well. We employ techniques such as random resized cropping, rotation, and color jittering to simulate different scenarios and lighting conditions. This is done using PyTorch’s transformation functions applied during the preprocessing stage of the input data, in order to further improve the robustness of the model against variations in new images.
Our approach builds upon the established efficacy of ResNet architectures but introduces specific adaptations and a fine-tuning methodology that is tailored for real-time gesture recognition in control interfaces. The primary innovation in our approach lies in the integration of ResNet with few-shot learning techniques, optimizing the network to perform well even with a limited amount of gesture data. This adaptation is crucial, as traditional deep learning methods often require large datasets, which are not always feasible to gather in specialized applications like gesture-based robotic control.
The use of a pretrained network allows us to benefit from previously learned features that are broadly applicable in visual recognition tasks, thus bypassing the need for extensive training from scratch. By unfreezing the last two convolutional blocks and introducing dropout before the final classification layer, our model is tailored to fine-tune its learning on the more nuanced aspects of gesture recognition. We expect that this focused learning, combined with robust data augmentation, will enable the model to effectively distinguish between similar gestures and perform accurately in diverse real-world settings.
The choice of ResNet-18, coupled with our dataset-specific adaptations and training strategies, addresses the limitations identified in previous literature—particularly the need for high accuracy and low-latency recognition in gesture-controlled interfaces. This makes this model potentially suitable for applications requiring quick and reliable gesture recognition, such as in controlling robots or other automated systems.
3.3.3 MediaPipe System
Model Overview. As talked about in the Data Preprocessing section and shown in Figure 3, MediaPipe is a cutting-edge machine learning framework for building multimodal applied machine learning pipelines, such as pose estimation and object classification. With the MediaPipe system, we decided to try something different. This implementation does not use few shot learning and we do not attempt to classify any gestures. Instead, we use the pose estimation model offered by MediaPipe, which gives 21 hand landmarks, to develop a control system for virtual robots. Instead of static images, we use a webcam feed with MediaPipe at 10 Hz and process each frame’s landmark to extract the control scheme.
Model Output. As MediaPipe only supplies the hand landmarks, we need a way to extract a feature that would make the pose estimator useful for our simulation. In our case, we extracted the wrist (marker 0) and middle finger tip (marker 12) as shown in Figure 3. The hand landmarks are supplied in a coordinate system using a normalized image coordinate frame [0,1] and an estimated z (depth value). We used the x and y coordinates of the two landmarks to create a vector that would be compared against the negative y-axis. We compare the vector and negative y-axis using the dot product to get the estimated angle of your hand. This angle would directly relate to the angular acceleration control shown later. We also used the estimated depth value from the wrist landmark to control the linear acceleration. This system allows a user to easily rotate, push and pull the hand from the camera to control a robot.
4. Experiment Setup
4.1.1 Siamese Network Training
For training the Siamese Network, we experimented with the following (variations of these approaches were used throughout training):
- Data preprocessing
- For some of our training process with the Siamese Network, we used MediaPipe to crop out the hand with some margin. This would hopefully allow the model to focus on the hand and discard any other features.
- PyTorch’s Auto Augmentation. This method applies an optimized series of transforms that was tested with other datasets and successful.
- Dataset Structure
- Our final dataset comes from all group members taking images of the gesture classes. We generated 89 images that were roughly evenly distributed among the classes.
- We experimented with different splitting methods and structures. For example our initial training consisted of 3-shot learning with 6 classes which created a support set of 18 images. We also experimented with 3-shot learning with 5 or 4 classes with suspicion that one or two classes may be too similar and confusing the model.
- Because our model compares each query to every image in the support set, we are able to generate significantly more data points compared to other methods. To calculate the number of possible training/testing points, we simply take the number of images in the support set and multiply it by the query. For example, our 3-shot, 5 class train set takes 37 query images and 15 support images to generate 675 data points. For our 3-shot, 6 class train set, we were able to make 846 data points from 18 images in our support set and 47 in our query set. Our train and test query set were split roughly 67%/33% and the support sets were identical between both classes as we are not trying to make a generalized few shot learning model.
- Pre-trained model architectures
- We tried our Siamese Network with different feature extractors: AlexNet, ResNet, and OpenPose. AlexNet and ResNet are primarily used for object classification and OpenPose is an Open Source model that detects hand landmarks like MediaPipe. We tried OpenPose’s direct output and also removed the last fully connected layer like AlexNet and ResNet.
- Data Balancing
- For training, we attempted to balance the dataset. because we are looking for the similarity between two images with multiple classes. So there will only be [1 / # of classes] that are labeled similar. Because of this, we have a dataset where only ⅙ of our data is labeled similar (1), and ⅚ labeled different (0). This could cause favoritism for the model to choose the different label. So, we attempted to balance the dataset using PyTorch’s WeightedRandomSampler.
- FC Layer Architecture
- We attempted to change the fully classified layer architecture to see if that would improve performance. For example, we attempted to increase the layers, add dropout to prevent overfitting, and pooling to shrink down the parameters to increase training speed.
- PyTorch Optimizers
- We experimented with different optimizers such as SGD, Adam and Adadelta. Adadelta was used in the PyTorch example. Adam and SGD were experimented with due to their popularity.
- PyTorch Scheduler
- The scheduler is used to gradually decrease the learning rate after a certain number of epochs. We initially left this out, but tried it out to see how it affects performance.
- Layer Freezing
- Because our feature extractor was pretrained, we also tried to freeze our feature extractor to see if that would affect performance.
- Hyperparameter Tuning
- We adjusted the hyperparameters in an attempt to find the optimal parameters for our model’s performance. We mainly adjusted the learning rate, batch size, and epochs.
Unfortunately, trying out all these experiments did not improve the performance of our Siamese Network model and we are not able to fully tell if most of these adjustments improved or harmed the performance as every training session met the fate of classifying only 0/1 or the accuracy crashed over training epochs. There were also a few cases where the testing accuracy wildly fluctuated but the classification performance was poor. Our model output is only supposed to output a 1 or 0 which tells us if the 2 input images (one from the support set and one from the query set) are similar or not (See Figure 4 for a visual representation of our model input and outputs). We were not able to get a model that reliably guessed both 0 (not similar) and 1 (similar). The model either decided to predict all 1s or all 0s. For evaluating the performance of the Siamese network we relied on the training loss, testing loss, accuracy, and the confusion matrix. The loss plots were to ensure that we were at least decreasing over epochs, and the accuracy/confusion matrix were to verify if our model was actually predicting values of both 0 (not similar) and 1 (similar).
4.1.2. ResNet Training
The primary goal of our experiment was to fine-tune the pretrained ResNet model to improve its performance and accuracy in detecting the predetermined hand gestures. By customizing the model to our dataset and needs, we aimed to demonstrate that our approach could achieve high accuracy in gesture recognition, surpassing existing methods by adapting to the nuances of robotic control gestures.
- Dataset Structure
- Our dataset comprises images captured using high-resolution webcams, focusing on six specific gesture classes essential for robot control. The training set was specifically designed for few-shot learning, containing 5 images per class across 6 classes, totaling 30 images. The images were randomly selected and distributed to ensure uniformity. The remaining images constituted the testing/validation set.
- Data preprocessing
- Each image was preprocessed to detect and isolate the hand using the MediaPipe framework, enhancing the model’s focus and performance by reducing background noise and irrelevant features.
- Data Transforms & Augmentation
- To enhance model robustness and generalization, we applied various data augmentation techniques during preprocessing. These included random resizing, cropping, and color adjustments. However, we observed that rotations, even less than 20 degrees, adversely affected the model’s performance, likely due to the orientation-sensitive nature of hand gestures.
- Pytorch Optimizers
- We evaluated various optimizers including SGD, Adam, and Adadelta to determine the most effective for our model. While Adadelta was featured in the PyTorch examples, we found that Adam significantly outperformed the others, likely due to its efficient handling of sparse gradients and adaptive learning rate capabilities.
- PyTorch Scheduler
- We incorporated a learning rate scheduler to reduce the learning rate progressively after every few epochs. This strategy aimed to refine the learning process in later stages, allowing for subtle adjustments in model weights and improving convergence on optimal values.
- Regularization
- L2 regularization was introduced to prevent overfitting, which is particularly important given the relatively small size of our training dataset. By penalizing the magnitude of model coefficients, L2 regularization ensured that our model generalized better to new, unseen data.
- Dropout Layer(s)
- Experimentation with a dropout layer was conducted to explore its impact on model training under a few-shot learning scenario. While dropout generally helps in preventing overfitting by randomly disabling neurons during training, we found that a high dropout rate (0.5) could lead to underfitting in our small dataset, necessitating a balance in its application - we decided to omit it from our implementation.
- Layer Unfreezing
- Initially, all layers of the ResNet model were frozen except for the last layer. To enhance learning specific to our gesture recognition tasks, we unfroze the last two sets of residual convolutional blocks (see Figure 5). This adjustment allowed the model to better adapt to the intricacies of hand gesture features, which was reflected in improved accuracy.
- Hyperparameter Tuning
- Hyperparameters such as the number of epochs, batch size, learning rate, and the L2 regularization term were meticulously tuned. Given the constraints of few-shot learning, a smaller for L2 regularization was preferred to avoid overly penalizing the model, which could hinder effective learning from a limited number of training samples.
Our model’s performance was primarily evaluated using accuracy, precision, recall, and the F1 score—metrics that provide a comprehensive view of classification performance. We also utilized a confusion matrix to visually assess the model’s performance across different classes, helping identify any specific biases or weaknesses in class predictions. Success in our experiments is quantified by achieving high values in accuracy and F1 score. These metrics were chosen because they balance the consideration of both precision and recall, providing a holistic view of model performance across all classes.
4.2 Gesture Controller Robot Simulations
The capabilities of gesture-based controllers are qualitatively evaluated using a simulated robotic platform. The goal of this experiment is to determine how effective different gesture-based controllers are at actually translating gesture-based input into desired robotic actuation. A differential drive robot in a Gazebo simulated environment is used as the target platform, as differential drive robots have simple kinematics and control inputs, and open-source software stacks and simulation environments are readily available. A differential drive robot individually controls the speeds of two powered wheels. By varying the relative speeds of each wheel, the robot is able to control both its linear velocity and angular velocity.
Our gesture-based controllers are built upon the Turtlebot3 software stack [15], which includes low-level drivers that translate commanded linear and angular velocities to explicit motor control. Our gesture-based controllers translate gesture commands into linear and angular velocity, which are then processed by the underlying Turtlebot3 stack into actual motion of the Turtlebot3 platform.
The gesture-based controllers used have the same basic structure, however differ slightly depending on the output of the detention method used. Both use raw video feed as input, and output two values: the desired linear and angular velocity. Individual frames are received from the camera near 10 Hz, resulting in an updated gesture command at the same sample rate. However, to smooth motion, linear and angular velocity commands are decoupled from gesture commands, with the gesture controller publishing these commands at 100 Hz. $\newline$
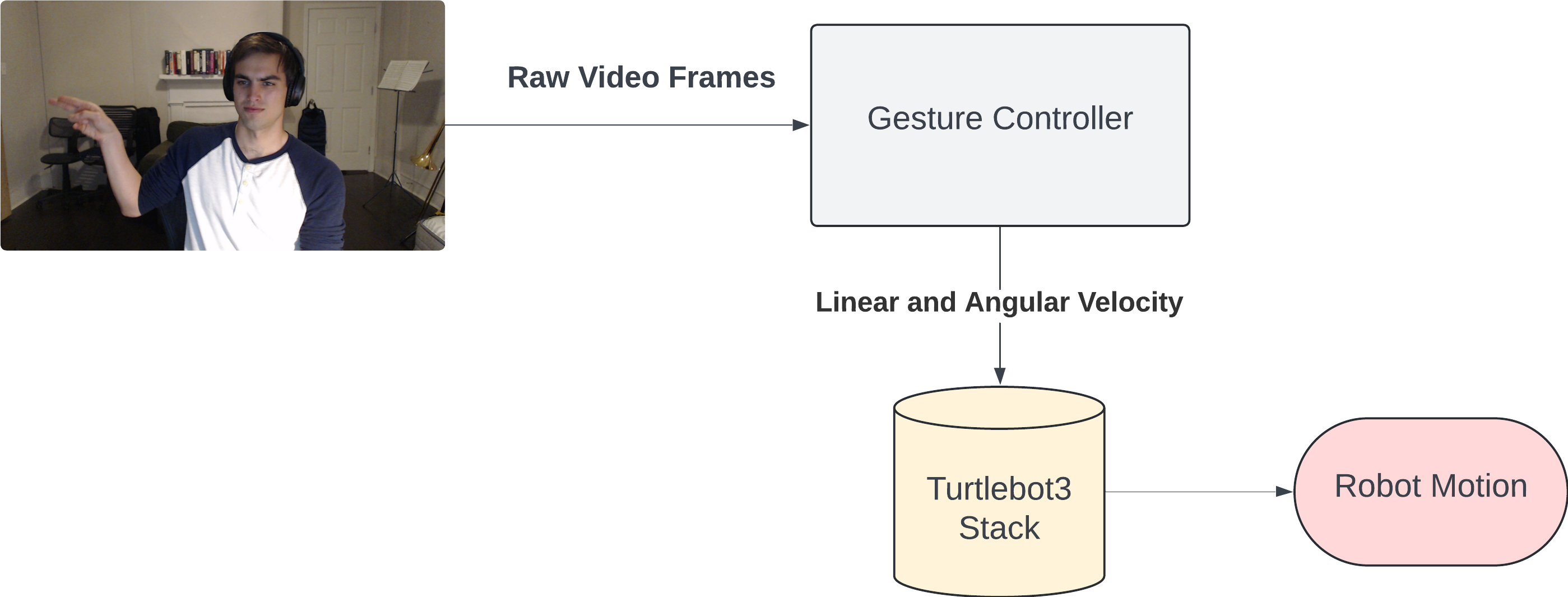 Figure 6: The input and outputs of the generic gesture controller.
Figure 6: The input and outputs of the generic gesture controller.
The two gesture controllers tested differed in the output of the gesture recognizer. Our gesture controller based on the ResNet Classification Model directly maps classified gestures to specific linear or angular velocities. For example, a gesture classified as “Straight” would result in a commanded linear velocity of 0.2 m/s, while a gesture classified as “left” would result in a commanded angular velocity of 0.5 rad/s. Any “stop” gestures, or undetermined gestures, would result in both linear and angular velocities set to 0. A disadvantage of this controller is the mutually exclusive nature of the classifications, and thus the commands. In some ways, this is desirable, for example, when the user wants to stop the robot’s motion. However it is undesirable in that it limits the ability to create dynamic movements, and limits the possible trajectories of the Turtlebot3 to straight line paths.
The gesture controller based on the MediaPipe addresses the issue of mutually exclusive commands by utilizing orthogonal measurements: hand angle and wrist position. A user can simultaneously vary both of these measurements to compose dynamic motions. In addition, by using these measurements directly, proportional control can be used to scale the magnitude of the control relative to the magnitudes of the hand and and wrist positions, e.g. as the hand is angled more, a larger angular velocity is commanded, leading to a faster turn.
While there is no specific expected output for these experiments, a successful experiment is one in which a user is able to easily control the Turtlebot3, successfully navigating around obstacles while executing the desired commands. The simulation environment is picked to facilitate these tests, with numerous of obstacles that require intentional and specific control inputs to navigate through. $\newline$
Figure 7: Gazebo simulation environment used for experimental testing.
5. Results
5.1 Model Training & Performance
5.1.1. Siamese Network Results
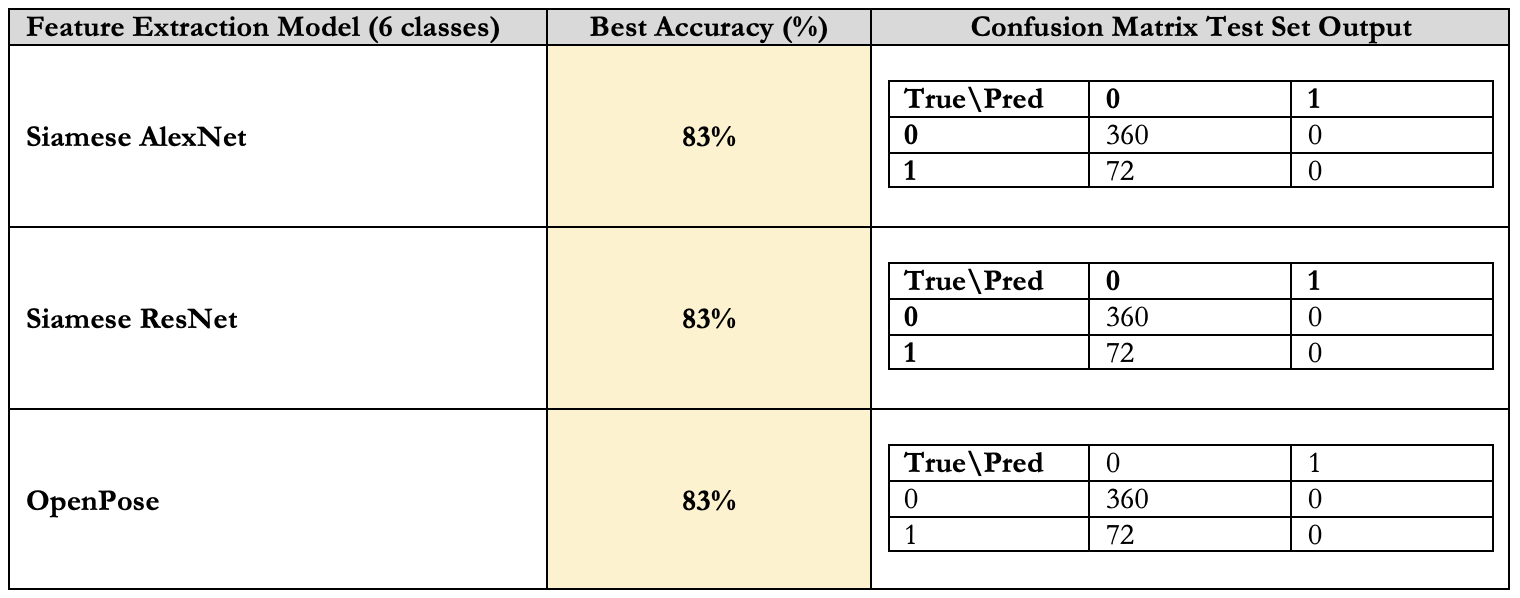
The performance of the Siamese Network is presented in the table and reveals that while the Siamese AlexNet, Siamese ResNet, and OpenPose all reported a high accuracy rate of 83%, a closer inspection of the underlying confusion matrices exposes a critical flaw in their predictive capabilities. Each model predominantly identifies gestures as the ‘not similar’ label, which may initially suggest effective performance. However, this outcome largely stems from an inherent imbalance within our dataset, specifically skewed by the method of labeling similarities across six classes. The statistical implication of this imbalance is that a strategy of consistently predicting the ‘not similar’ category would yield a correct prediction approximately five-sixths of the time, merely due to the probability distribution of the labels, rather than genuine learning or discernment by the models.
With 83% accuracy, the Few-Shot Learning model was mostly ‘successful’ in terms of accuracy, but not practicality as shown in Figure 8 and confusion matrix.
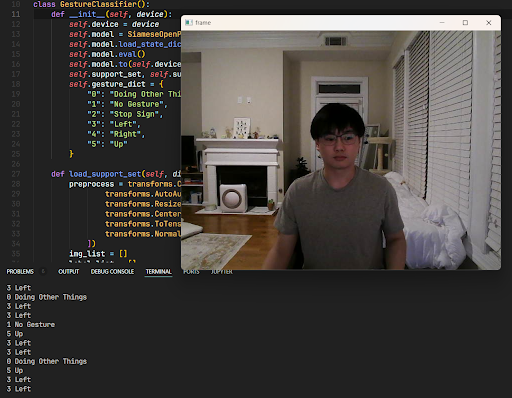
Figure 8: Qualitative Example of the Siamese Network Performance.
5.1.2 ResNet Results
Performance of the ResNet is shown in Figure 9 and Figure 10. The final training accuracy was 100% and the trend was a sharp rise in accuracy until it reached about 93% accuracy. From there, the accuracy kept moving in small increments both up and down. The final validation accuracy is 59% with a trend of a moderate increase from around 26% to 49%. The accuracy remained between 48% and 59% for the remaining epochs. The loss for the training data dropped drastically for the training data from 2.1342 in the first epoch to 0.0333 in the final epoch. Analyzing the loss and the accuracy of the training data shows that the model became very proficient in analyzing gestures from the training dataset. However, the validation loss had a less clear trend where it decreased until about epoch 14 where it began to fluctuate. This information, in conjunction with the training information shows that there is overfitting occurring. This can be attributed to our small dataset which we were using for Few-Shot Learning.
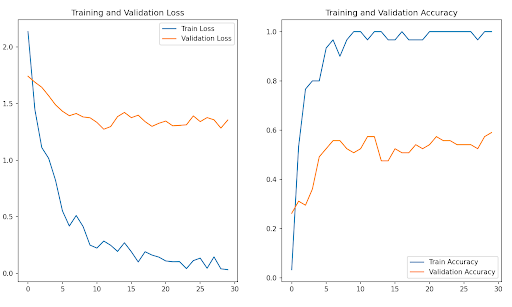
Figure 9: Training and Validation Loss and Accuracy Graphs for ResNet
Looking at the F1 score, there was a similar trend to the validation accuracy where it starts at 0.23 in the first epoch and then peaks at 0.56 in the final epoch. It rose gradually until about epoch 9 where it began to fluctuate. This shows an improving but imperfect balance between precision and recall in the model’s performance on validation data.
What can be concluded from this data is that the model is overfitting due to the very high training accuracy and a fluctuating validation accuracy. To improve this, more data can be added to prevent overfitting or other architectures, particularly Few-Shot Learning architectures, could be used to prevent overfitting and increasing accuracy.
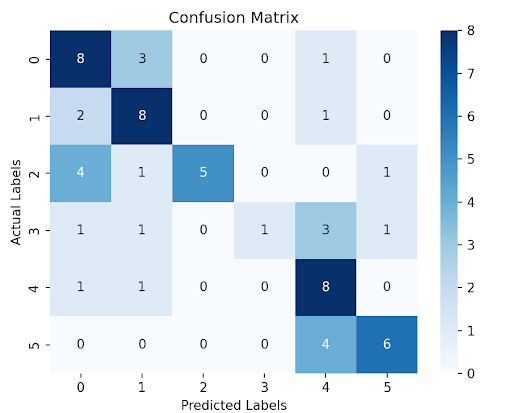
Figure 10: Confusion Matrix for the ResNet
5.2 Gesture Controller Robot Simulations
Performance of both Gesture Controllers are shown in the videos below, with both the raw video input, the commanded linear and angular velocities, and the resulting robotic motion. Qualtativly, inaccurate command classifications made it difficult to accurately turn, drive, or stop the Turtlebot3 with any fine motions. That being said, partial control of the Turtlebot3 with the RestNet based gesture controller is possible, with the user controlling the robot able to avoid collisions with obstacles. That being said, it is quite obvious that the mediapipe controller significantly outperformed the RestNet based gesture controller. The accuracy of the finger pose detection dramatically helped effectively determining the desired commands, and the ability to compose both linear and angular velocity into a single control input enabled smooth motion control around obstacles.
Video 1: Controlling a Turtlebot3 using a Resnet-based Gesture Controller
Video 2: Controlling a Turtlebot3 using our MediaPipe-based Gesture Controller
5.3 Comparisons to Prior Work
When looking at our results compared to other results, our Few-Shot Learning model performed ok when looking at our accuracy at 83% for the recognition of four gestures and two other classes (no gesture and other gesture). However, Schlüsener and Bücker’s FSL model performed slightly better at 88.8% accuracy for recognition of five gestures and 81.2% for ten gestures [5]. Many insights can be gained from looking at the comparison of the accuracy between our models. First and foremost, the FSL architecture that we used was the Convolutional Siamese Network, whereas the architecture used by Schlüsener and Bücker was a Relation Network. The implementation of these architectures could be the potential reason for these results. In addition, our dataset consisted of static gestures rather than dynamic gestures which can also have other ramifications. In addition, though our accuracy may be high, the confusion matrix was still not accurate implying some underlying issues. This should also be noted but is harder to quantify.
6. Discussion
In this project, we explored the integration of few-shot learning into robotic control by attempting to classify gestures with limited examples from each class to drive a simulated TurtleBot 3. We developed two models, with one of our few-shot learning approaches achieving partial success. Ultimately, we successfully implemented a control method in simulation using the MediaPipe hand detection system, which proved to be an enjoyable and educational experience.
Throughout this project, we gained valuable insights into few-shot learning methods and their implementation. We also deepened our understanding of PyTorch, exploring advanced features such as scheduling. We remain optimistic about the potential of few-shot learning for gesture classification and robotic control. In future work, on the gesture recognition models, we aim to investigate alternative few-shot learning approaches, such as prototypical and mobile networks, to enhance our system’s effectiveness. On the robotics side, we aim to further improve our simulation testing by quantitative metrics like evaluating sensitivity and accuracy of our method by checking the deviation from the predetermined path. We also could make more challenging simulation scenarios like controlling a 6-DOF robot using gestures. Finally, we would also test our implementation on real hardware.
We encountered several challenges during the project. Training on Apple Metal presented difficulties, particularly with the Siamese Network on ARM-based Macs. Integrating our models with the Robot Operating System (ROS) was complicated by dependency issues with MediaPipe, which required significant troubleshooting. Additionally, the selection and testing of gestures in simulation revealed that some gestures, such as the up and stop gestures, were too similar, leading to confusion.
Reflecting on our experiences, we believe that starting with simpler, more distinct gesture selections would have been advantageous. A more streamlined focus on fewer architectures might have allowed us more time to explore and compare various few-shot learning methods, ultimately selecting the most effective model. Starting with a basic implementation like MediaPipe and incrementally building complexity could have provided a clearer baseline for measuring performance improvements.
This project not only enhanced our technical skills but also provided lessons in project management and the importance of methodical, incremental testing.
7. References
[1] H. Zhao, J. Hu, Y. Zhang, and H. Cheng, “Hand gesture based control strategy for mobile robots,” in Proceedings of the 2017 29th Chinese Control And Decision Conference (CCDC), Chongqing, China, 2017, pp. 5868-5872. doi: 10.1109/CCDC.2017.7978217.
[2] Google, “Gesture Recognizer,” Google Developers. Accessed: 02.22.2024. [Online]. Available: https://developers.google.com/mediapipe/solutions/vision/gesture_recognizer.
[3] A. Vysocký, T. Poštulka, J. Chlebek, T. Kot, J. Maslowski, and S. Grushko, “Hand Gesture Interface for Robot Path Definition in Collaborative Applications: Implementation and Comparative Study,” Sensors, vol. 23, no. 9, Art. no. 4219, 2023. https://doi.org/10.3390/s23094219.
[4] A. Parnami and M. Lee, “Learning from few examples: A summary of approaches to few-shot learning,” arXiv.org. https://arxiv.org/abs/2203.04291.
[5] N. Schlüsener and M. Bücker, “Fast Learning of Dynamic Hand Gesture Recognition with Few-Shot Learning Models,” arXiv.org. https://arxiv.org/pdf/2212.08363.
[6] H. Sajid, “Few shot learning in Computer Vision: Approaches & Uses,” Encord. Accessed: 03.25.2024. [Online]. Available: https://encord.com/blog/few-shot-learning-in-computer-vision.
[7] E. Rahimian, S. Zabihi, A. Asif, S. F. Atashzar and A. Mohammadi, “Trustworthy Adaptation with Few-Shot Learning for Hand Gesture Recognition,” 2021 IEEE International Conference on Autonomous Systems (ICAS), Montreal, QC, Canada, 2021, pp. 1-5, doi: 10.1109/ICAS49788.2021.9551144.
[8] Qualcomm, “Gesture recognition dataset: Jester,” Qualcomm Developer Network. Accessed: 03.13.2024. [Online]. Available: https://developer.qualcomm.com/software/ai-datasets/jester.
[9] Google, “Hand landmarks detection guide,” Google Developers. Accessed: 03.20.2024. [Online]. Available: https://developers.google.com/mediapipe/solutions/vision/hand_landmarker.
[10] A. Dutt, “Siamese Networks Introduction and Implementation - towards Data Science,” Medium, Aug. 01, 2022. [Online]. Available: https://towardsdatascience.com/siamese-networks-introduction-and-implementation-2140e3443dee
[11] E. D. Cubuk, B. Zoph, D. Mané, V. Vasudevan and Q. V. Le, “AutoAugment: Learning Augmentation Strategies From Data,” 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 2019, pp. 113-123, doi: 10.1109/CVPR.2019.00020.
[12] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” arXiv.org, Dec. 10, 2015. https://arxiv.org/abs/1512.03385
[13] “Regularization for simplicity: L2 regularization,” Google for Developers. https://developers.google.com/machine-learning/crash-course/regularization-for-simplicity/l2-regularization
[14] “Loss Functions — ML Glossary documentation.” https://ml-cheatsheet.readthedocs.io/en/latest/loss_functions.html
[15] “TurtleBot3.” https://www.turtlebot.com/turtlebot3/